
pandas 모듈을 이용하여 편의점 csv 파일을 만들것이다. (jupyter nootbook)
jupyter nootbook을 사용하면 print을 안써도된다 기타 사용법은 알아서 찾아보시길
그 전에 짧은 txt 하나 테스트
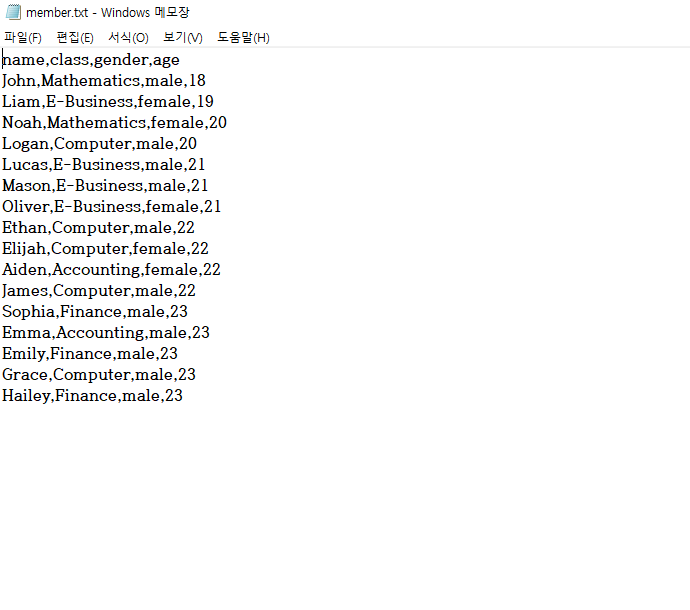
member = pd.read_csv('member.txt')
member

주의할점 Visual Studio Code로 작업할때 txt파일 위치의 절때경로를 써주던가 상대경로를 써줘야하는데
절때경로(C:/user/~~~)는 상관없으니 상대경로는 실행시키는 위치에 따라 인식이 안되는 경우가 많다
import sys
import os
dir = os.path.dirname(os.path.realpath(__file__))
data = dir + '/member.txt'이런식으로 사용하면 상대경로만 지정해도 사용할 수 있다.
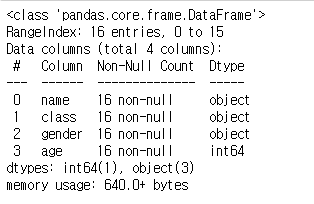
1. 대략적인 member 정보
member.info()
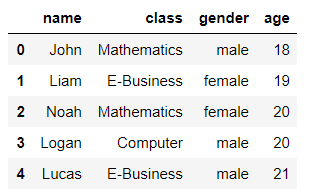
2. 상위 5개 출력
member.head(5)
3. 하위 5개 출력
member.tail(5)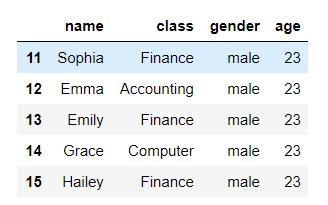
4. 선택한 컬럼만 상위 5개 출력
member[['name','class']].head(5)

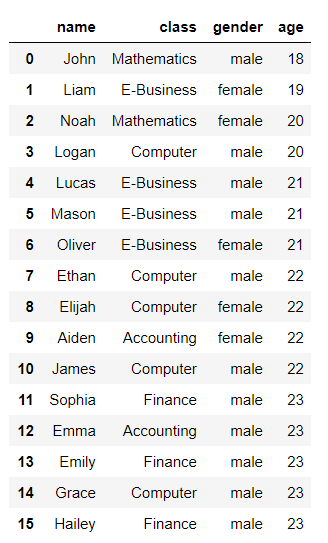
5. 인덱스 전 범위 출력
member[:]
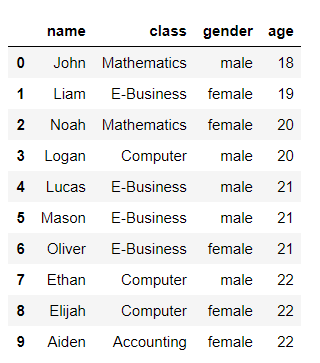
6. 인덱스 10개 출력
member[:10] #인덱스는 0번부터 시작 9번까지 총10개
7. 인덱스 3번째부터 10번째까지 출력
member[3:10] #파이썬에선 3:10이면 3부터 9까지임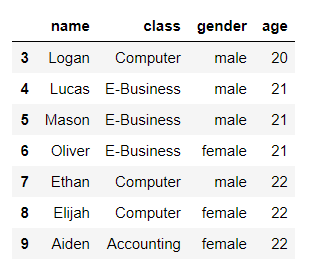
8. 인덱스 3번째부터 10번째까지 특정 컬럼 출력
member[3:10][['gender','age']] #뒤에 []하나씩 더붙음

9. 인덱스 3번째 정보
member.loc[3]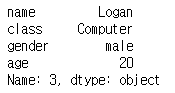
10. 인덱스 3번째부터 10번째까지 정보
member.loc[3:10]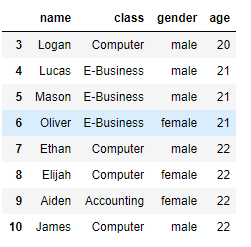
11. 인덱스 3번째부터 10번째까지 정보
member.iloc[3:10]
12. 인덱스 3번째까지 0번 컬럼부터 1번 컬럼까지 (loc는 컬럼명을 사용해야함)
member.iloc[:3,0:2] #loc는 숫자로 사용 불가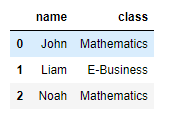
13. 행 삭제
member.drop([3] , axis=0) #axis 0은 행 기준삭제 default가 0이므로 안써도됨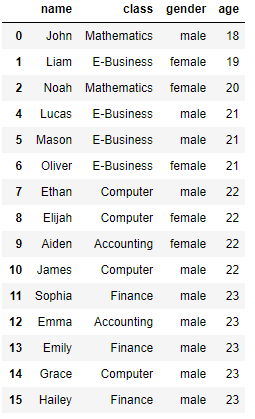
14. 행 삭제후 index값 재정렬
member.drop([3] , axis=0).reset_index()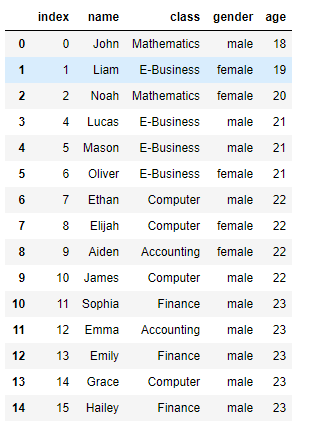
15. 열 삭제
member.drop(['name'] ,axis=1)

16. 중복값 제거
member.drop_duplicates(['class'])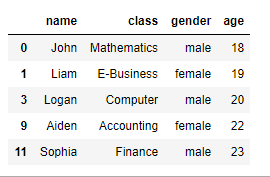
17. 나이가 20상 이상이면서 성별이 남자인 경우
member[(member.age > 20) & (member.gender == 'male')]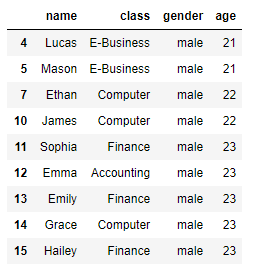
18. 성별별 인원수
member.gender.value_counts()
pandas 모듈을 이용하여 편의점 csv 파일을 만들것이다. (jupyter nootbook)
jupyter nootbook을 사용하면 print을 안써도된다 기타 사용법은 알아서 찾아보시길
그 전에 짧은 txt 하나 테스트
member = pd.read_csv('member.txt')
member
주의할점 Visual Studio Code로 작업할때 txt파일 위치의 절때경로를 써주던가 상대경로를 써줘야하는데
절때경로(C:/user/~~~)는 상관없으니 상대경로는 실행시키는 위치에 따라 인식이 안되는 경우가 많다
import sys
import os
dir = os.path.dirname(os.path.realpath(__file__))
data = dir + '/member.txt'이런식으로 사용하면 상대경로만 지정해도 사용할 수 있다.
1. 대략적인 member 정보
member.info()
2. 상위 5개 출력
member.head(5)
3. 하위 5개 출력
member.tail(5)4. 선택한 컬럼만 상위 5개 출력
member[['name','class']].head(5)
5. 인덱스 전 범위 출력
member[:]
6. 인덱스 10개 출력
member[:10] #인덱스는 0번부터 시작 9번까지 총10개
7. 인덱스 3번째부터 10번째까지 출력
member[3:10] #파이썬에선 3:10이면 3부터 9까지임
8. 인덱스 3번째부터 10번째까지 특정 컬럼 출력
member[3:10][['gender','age']] #뒤에 []하나씩 더붙음
9. 인덱스 3번째 정보
member.loc[3]
10. 인덱스 3번째부터 10번째까지 정보
member.loc[3:10]
11. 인덱스 3번째부터 10번째까지 정보
member.iloc[3:10]
12. 인덱스 3번째까지 0번 컬럼부터 1번 컬럼까지 (loc는 컬럼명을 사용해야함)
member.iloc[:3,0:2] #loc는 숫자로 사용 불가
13. 행 삭제
member.drop([3] , axis=0) #axis 0은 행 기준삭제 default가 0이므로 안써도됨
14. 행 삭제후 index값 재정렬
member.drop([3] , axis=0).reset_index()
15. 열 삭제
member.drop(['name'] ,axis=1)
16. 중복값 제거
member.drop_duplicates(['class'])
17. 나이가 20상 이상이면서 성별이 남자인 경우
member[(member.age > 20) & (member.gender == 'male')]
18. 성별별 인원수
member.gender.value_counts()