
편의점 csv 활용편
1. csv파일내용 fd에 담고 출력
import pandas as pd
fd = pd.read_csv('convenient_store.csv')
fd #visual code에선 print(fd)
2. 전체 컬럼 정보, null 값 유무 확인
fd.columns.tolist()
3. null 값 유무 확인 (False = 없는것)
fd.isnull()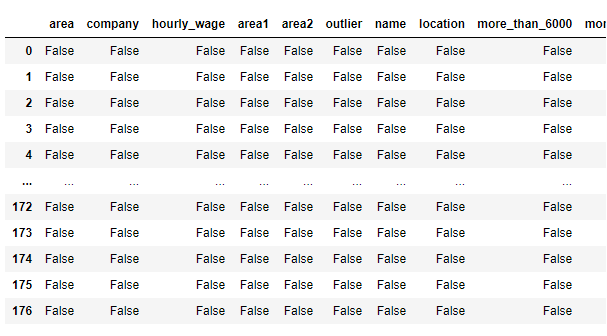
4. null 값 유무 확인 (True= 없는것)
fd.notnull()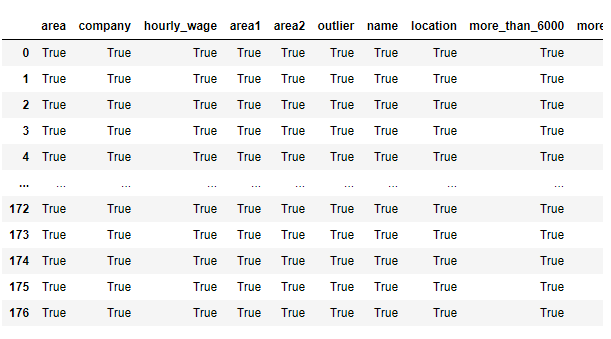
5. 개수, 평균, 편차, 최소, 최대값 확인
fd.describe()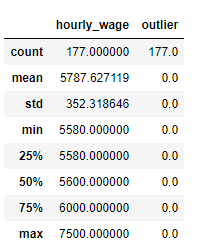
6. 지역에 대한 통계, 개수, 유니크한 정보, 제일 빈도가 높은 지역
a = fd['hourly_wage'].groupby(fd['area']) #hourly_wage , area
a.max()
7. 시간 당 급여가 6500원 이상인 지역의 편의점 정보 출력 (상위 10개만)
fd[(fd.hourly_wage > 6500)]['company'].head(10)
8. 시간 당 급여가 높은 순서로 정렬 (상위 10개만 출력)
fd.sort_values(by='hourly_wage', ascending=0).head(10)
9. 영등포구에서 시간 당 급여가 6000원 이상인 편의점 검색
y_high_wage = fd[(fd.hourly_wage >= 6000) & (fd.area1 == '영등포구')]
y_high_wage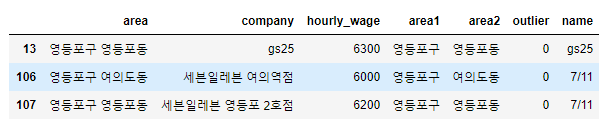
10. CU 편의점만 출력 (상위 10개만)
cu = fd[fd.company.str.contains('CU')]
cu.head(10)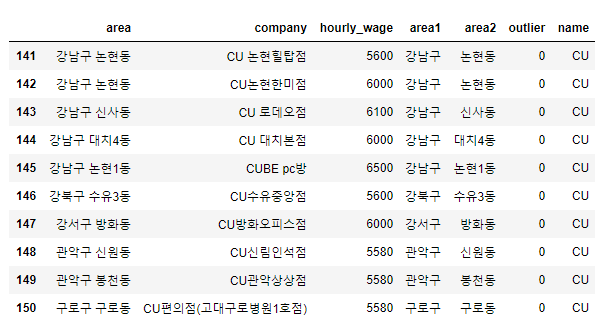
11. 지역 컬럼(location)을 추가한 다음, in Seoul 이라는 값 저장, 상위 5개 출력
fd['location'] = 'in Seoul'
fd.head(5)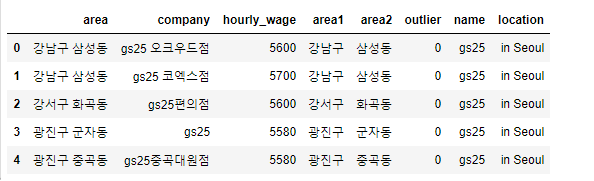
12. 6000원 이상 컬럼 추가(more_than_6000) -> True, False 값 저장 (상위 10개 출력)
fd['more_than_6000'] = (fd['hourly_wage'] >= 6000)
fd.head(10)
13. more_than_6000 컬럼에서 True인 데이터들의 평균, 개수, 편차 등의 정보 출력
fd[fd['more_than_6000'] == True].describe()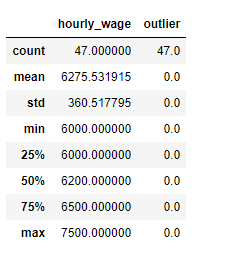
14. more_than_6000 이름의 함수를 생성하고, 6000원이상인 경우 A group, 아니면 B group을 반환하는 함수 생성
def more_than_6000(x):
if x >= 6000:
return 'A group'
else :
return 'B group'
15. more_than_6000_f 컬럼 생성하고 more_than_6000 함수의 결과를 저장후 상위 10개 출력
fd['more_than_6000_f'] = fd.hourly_wage.map(lambda x : more_than_6000(x)))
fd.head(10)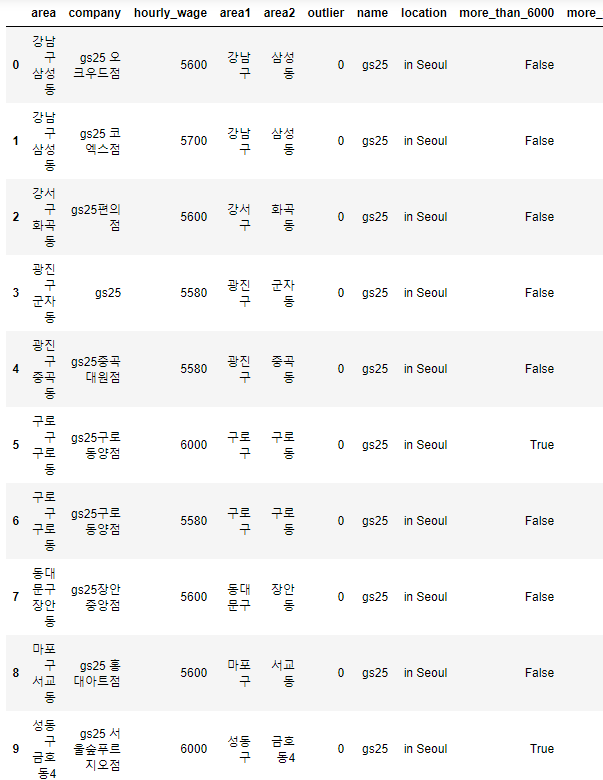
편의점 csv 활용편
1. csv파일내용 fd에 담고 출력
import pandas as pd
fd = pd.read_csv('convenient_store.csv')
fd #visual code에선 print(fd)
2. 전체 컬럼 정보, null 값 유무 확인
fd.columns.tolist()
3. null 값 유무 확인 (False = 없는것)
fd.isnull()
4. null 값 유무 확인 (True= 없는것)
fd.notnull()
5. 개수, 평균, 편차, 최소, 최대값 확인
fd.describe()
6. 지역에 대한 통계, 개수, 유니크한 정보, 제일 빈도가 높은 지역
a = fd['hourly_wage'].groupby(fd['area']) #hourly_wage , area
a.max()
7. 시간 당 급여가 6500원 이상인 지역의 편의점 정보 출력 (상위 10개만)
fd[(fd.hourly_wage > 6500)]['company'].head(10)
8. 시간 당 급여가 높은 순서로 정렬 (상위 10개만 출력)
fd.sort_values(by='hourly_wage', ascending=0).head(10)
9. 영등포구에서 시간 당 급여가 6000원 이상인 편의점 검색
y_high_wage = fd[(fd.hourly_wage >= 6000) & (fd.area1 == '영등포구')]
y_high_wage
10. CU 편의점만 출력 (상위 10개만)
cu = fd[fd.company.str.contains('CU')]
cu.head(10)
11. 지역 컬럼(location)을 추가한 다음, in Seoul 이라는 값 저장, 상위 5개 출력
fd['location'] = 'in Seoul'
fd.head(5)
12. 6000원 이상 컬럼 추가(more_than_6000) -> True, False 값 저장 (상위 10개 출력)
fd['more_than_6000'] = (fd['hourly_wage'] >= 6000)
fd.head(10)
13. more_than_6000 컬럼에서 True인 데이터들의 평균, 개수, 편차 등의 정보 출력
fd[fd['more_than_6000'] == True].describe()
14. more_than_6000 이름의 함수를 생성하고, 6000원이상인 경우 A group, 아니면 B group을 반환하는 함수 생성
def more_than_6000(x):
if x >= 6000:
return 'A group'
else :
return 'B group'
15. more_than_6000_f 컬럼 생성하고 more_than_6000 함수의 결과를 저장후 상위 10개 출력
fd['more_than_6000_f'] = fd.hourly_wage.map(lambda x : more_than_6000(x)))
fd.head(10)