

회사에선 1000개의 문서 10000개의 문서나 파일들이 정리가 안되는 경우가 있다.
개인도 마찬가지이다.
개인이 가지고 있는 파일이나 문서들이 정리가 안되는 모습을 볼 수 있다.
이러한 일들을 AI가 해주면 얼마나 편하고 빠르게 이루어질까의 의문에서 이 프로젝트가 시작되었다.
AI를 이용하여 파일 및 문서들을 분류하는 알고리즘을 간력하게 만들 것이다.
문서를 분류하는데 보통 문서의 제목으로 분류를 하거나 문서의 내용으로 분류를 한다.
앞으로 진행할 내용은 제목 기반으로 문서를 분류할 알고리즘을 만들 것이다.
제목 기반 분류 알고리즘은 파일과 문서등 어느 확장자에 상관없이 분류를 할 수 있다
내용 기반 분류 알고리즘 같은 경우에는 한글이나 워드, PDF, 엑셀 등 문서의 내용을 확인해야 하기에 일부 제약이 있을 수 있다.
사실상 제목 기반의 분류는 AI라고 부르기엔 모호한 부분이 있다.
하지만 여러번의 필터링과 Word2Vec를 이용하여 어설프지만 어느정도 분류가 되는 모습을 볼 수 있을것이다.
외국에서의 영어를 기반으로한 문서 분류 알고리즘은 종종 발견할 수 있으나
고유명사를 처리할 모델이 거의 없으며, 한글의 특성상 한글 기반 문서 분류 알고리즘은 만들기 쉽지 않았다는걸 프로젝트를 하면서 느꼈다
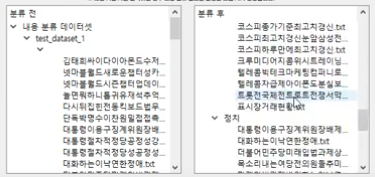
팀 프로젝트로 만든 분류 모델을 어플리케이션에 적용한 내용이다.
물론 어플리케이션 개발쪽은 내가 담당하지 않아 기술하지 않을 예정이다.
물론 잘 짜여진 코드도 아닐뿐더러 억지스럽게 느낄 수 있지만 공부한다는 개념으로 접근하였고 이 글을 읽은 다른 사람들이 더욱 알맞은 코드로 발전해 나아가주었으면 좋겠다.
블로그에 기재할 자동 문서 분류 알고리즘 순서는 다음과 같다
1. 형태소 분석
2. 단순 유사도 검사 (필터링)
3. 파파고 API를 통한 번역
4. 유사도 검사 모델 (Word2Vec)
5. 자모 단위 검사 (필터링)
6. 기타
1단계 : 사용자는 분류할 임의의 폴더명들을 지정한다.
2단계 : 분류할 파일들의 파일명을 형태소 분석을한다.
3단계 : 영어 파일명이 있을경우 파파고 API를 통해 한글로 번역한다.
4단계 : 폴더명과 파일명이 완전 일치하는 경우 폴더에 넣어준다, 없을 경우 다음 단계
5단계 : Word2Vec를 통해 폴더명과 파일명의 유사도 검사를 한다(기준치 설정), 없을 경우 다음 단계
6단계 : 폴더명과 파일명을 자모 단위로 쪼개어 비교한다, 없을 경우 다음 단계
7단계 : 마지막 남은 파일들이 있을 경우 기타 폴더에 넣어준다.
팀 프로젝트에선
한글 모델이 아닌 영어 모델을 사용
파일명 뿐만 아니라 문서들의 내용을 확인하여 비교하는 알고리즘
기존 프로세스보다 더 체계적인 프로세스를 만들었다.
하지만 해당 내용은 양이 너무 많아 초기 버전 프로세스 일부만 올리기로 하였다.

회사에선 1000개의 문서 10000개의 문서나 파일들이 정리가 안되는 경우가 있다.
개인도 마찬가지이다.
개인이 가지고 있는 파일이나 문서들이 정리가 안되는 모습을 볼 수 있다.
이러한 일들을 AI가 해주면 얼마나 편하고 빠르게 이루어질까의 의문에서 이 프로젝트가 시작되었다.
AI를 이용하여 파일 및 문서들을 분류하는 알고리즘을 간력하게 만들 것이다.
문서를 분류하는데 보통 문서의 제목으로 분류를 하거나 문서의 내용으로 분류를 한다.
앞으로 진행할 내용은 제목 기반으로 문서를 분류할 알고리즘을 만들 것이다.
제목 기반 분류 알고리즘은 파일과 문서등 어느 확장자에 상관없이 분류를 할 수 있다
내용 기반 분류 알고리즘 같은 경우에는 한글이나 워드, PDF, 엑셀 등 문서의 내용을 확인해야 하기에 일부 제약이 있을 수 있다.
사실상 제목 기반의 분류는 AI라고 부르기엔 모호한 부분이 있다.
하지만 여러번의 필터링과 Word2Vec를 이용하여 어설프지만 어느정도 분류가 되는 모습을 볼 수 있을것이다.
외국에서의 영어를 기반으로한 문서 분류 알고리즘은 종종 발견할 수 있으나
고유명사를 처리할 모델이 거의 없으며, 한글의 특성상 한글 기반 문서 분류 알고리즘은 만들기 쉽지 않았다는걸 프로젝트를 하면서 느꼈다
팀 프로젝트로 만든 분류 모델을 어플리케이션에 적용한 내용이다.
물론 어플리케이션 개발쪽은 내가 담당하지 않아 기술하지 않을 예정이다.
물론 잘 짜여진 코드도 아닐뿐더러 억지스럽게 느낄 수 있지만 공부한다는 개념으로 접근하였고 이 글을 읽은 다른 사람들이 더욱 알맞은 코드로 발전해 나아가주었으면 좋겠다.
블로그에 기재할 자동 문서 분류 알고리즘 순서는 다음과 같다
1. 형태소 분석
2. 단순 유사도 검사 (필터링)
3. 파파고 API를 통한 번역
4. 유사도 검사 모델 (Word2Vec)
5. 자모 단위 검사 (필터링)
6. 기타
1단계 : 사용자는 분류할 임의의 폴더명들을 지정한다.
2단계 : 분류할 파일들의 파일명을 형태소 분석을한다.
3단계 : 영어 파일명이 있을경우 파파고 API를 통해 한글로 번역한다.
4단계 : 폴더명과 파일명이 완전 일치하는 경우 폴더에 넣어준다, 없을 경우 다음 단계
5단계 : Word2Vec를 통해 폴더명과 파일명의 유사도 검사를 한다(기준치 설정), 없을 경우 다음 단계
6단계 : 폴더명과 파일명을 자모 단위로 쪼개어 비교한다, 없을 경우 다음 단계
7단계 : 마지막 남은 파일들이 있을 경우 기타 폴더에 넣어준다.
팀 프로젝트에선
한글 모델이 아닌 영어 모델을 사용
파일명 뿐만 아니라 문서들의 내용을 확인하여 비교하는 알고리즘
기존 프로세스보다 더 체계적인 프로세스를 만들었다.
하지만 해당 내용은 양이 너무 많아 초기 버전 프로세스 일부만 올리기로 하였다.