
목차
반응형
지난 시간에 파파고 API를 사용하여 번역을 하였는데 일부 고유명사의 경우 한글로 번역이 안되는 결과를 볼 수 있었다.
trans = get_translate("Skt")
trans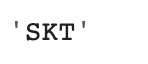
이러한 경우에만 영어 발음 그대로 자모단위 필터링을 해주려고 한다. (예시- 에스케이티)
import re
def simple_filter(input_text):
ENGS = ['a', 'A', 'b', 'B', 'c', 'C', 'd', 'D', 'e', 'E', 'f', 'F', 'g', 'G', 'h', 'H', 'i', 'I', 'j', 'J', 'k',
'K', 'l', 'L',
'm', 'M', 'n', 'N', 'o', 'O', 'p', 'P', 'q', 'Q', 'r', 'R', 's', 'S', 't', 'T', 'u', 'U', 'v', 'V', 'w',
'W', 's', 'S', 'y', 'Y', 'z', 'Z']
KORS = ['에이', '에이', '비', '비', '씨', '씨', '디', '디', '이', '이', '에프', '에프', '쥐', '쥐', '에이치', '에이치', '아이', '아이', '제이',
'제이',
'케이', '케이', '엘', '엘', '엠', '엠', '엔', '엔', '오', '오', '피', '피', '큐', '큐', '알', '알', '에스', '에스', '티', '티', '유',
'유', '브이', '브이',
'더블유', '더블유', '에스', '에스', '와이', '와이', '지', '지']
trans = dict(zip(ENGS, KORS)) # 영어와 한글을 대칭하여 딕셔너리화
is_english = re.compile('[-a-zA-Z]') # 영어 정규화
temp = is_english.findall(input_text) # 함수에 들어오는 인자가 영어가 있는경우 temp에 삽입
result_trans = []
if len(temp) > 0: # 영어가 temp에 존재하는 경우
result_trans = ''.join([trans[i] for i in temp]) # 영어를 한글자씩 한글로 매칭
return result_trans # 매칭된값 리턴
else:
return None발음 그대로 표기하여 매칭해주는 부분이다.
a = simple_filter("SKT")
a
확장
파파고 API를 사용하는데 고유명사 등 처리가 안될경우 그 부분만 번역을 해주어 리턴해주는 방법을 고안
파파고 API는 무료버전을 사용
import requests
def get_translate(text):
client_id = "" # <-- client_id 기입
client_secret = "" # <-- client_secret 기입
data = {'text' : text,
'source' : 'en',
'target': 'ko'}
url = "https://openapi.naver.com/v1/papago/n2mt"
header = {"X-Naver-Client-Id":client_id,
"X-Naver-Client-Secret":client_secret}
response = requests.post(url, headers=header, data=data)
rescode = response.status_code
if(rescode==200):
send_data = response.json()
trans_data = (send_data['message']['result']['translatedText'])
return trans_data
else:
print("Error Code:" , rescode)def start_trans(input_text):
ENGS = ['a', 'A', 'b', 'B', 'c', 'C', 'd', 'D', 'e', 'E', 'f', 'F', 'g', 'G', 'h', 'H', 'i', 'I', 'j', 'J', 'k',
'K', 'l', 'L',
'm', 'M', 'n', 'N', 'o', 'O', 'p', 'P', 'q', 'Q', 'r', 'R', 's', 'S', 't', 'T', 'u', 'U', 'v', 'V', 'w',
'W', 's', 'S', 'y', 'Y', 'z', 'Z']
KORS = ['에이', '에이', '비', '비', '씨', '씨', '디', '디', '이', '이', '에프', '에프', '쥐', '쥐', '에이치', '에이치', '아이', '아이', '제이',
'제이',
'케이', '케이', '엘', '엘', '엠', '엠', '엔', '엔', '오', '오', '피', '피', '큐', '큐', '알', '알', '에스', '에스', '티', '티', '유',
'유', '브이', '브이',
'더블유', '더블유', '에스', '에스', '와이', '와이', '지', '지']
trans = dict(zip(ENGS, KORS))
papago_trans = get_translate(input_text) # 파파고로 번역 데이터 보내기
is_english = re.compile('[-a-zA-Z]')
temp = is_english.findall(papago_trans) # 파파고에서 번역이 안된 영어 문장이 있다면 temp값 존재
result_trans = []
if len(temp) > 0: # 영어 데이터 존재 유무
result_trans = ''.join([trans[i] for i in temp])
return result_trans # 한글로 번역이 안된 데이터 존재
else:
return papago_trans # 한글로 번역이 잘된 데이터일 경우 그대로 리턴
a = start_trans("SKT")
a
기존에 영어 데이터가 없다면 파파고에서 출력된 값이 출력될 것이고 번역이 안됬다면 매칭된 결과값이 출력될 것이다.
a = start_trans("naver")
a

a = start_trans("SKT T1")
a
숫자 데이터 같은 경우에는 필터링되므로 필터 부분에 적당한 조율을 하면 될것 같다.
다음 편에선 파파고 API의 비동기화를 다뤄보겠다.
반응형
반응형
지난 시간에 파파고 API를 사용하여 번역을 하였는데 일부 고유명사의 경우 한글로 번역이 안되는 결과를 볼 수 있었다.
trans = get_translate("Skt")
trans
이러한 경우에만 영어 발음 그대로 자모단위 필터링을 해주려고 한다. (예시- 에스케이티)
import re
def simple_filter(input_text):
ENGS = ['a', 'A', 'b', 'B', 'c', 'C', 'd', 'D', 'e', 'E', 'f', 'F', 'g', 'G', 'h', 'H', 'i', 'I', 'j', 'J', 'k',
'K', 'l', 'L',
'm', 'M', 'n', 'N', 'o', 'O', 'p', 'P', 'q', 'Q', 'r', 'R', 's', 'S', 't', 'T', 'u', 'U', 'v', 'V', 'w',
'W', 's', 'S', 'y', 'Y', 'z', 'Z']
KORS = ['에이', '에이', '비', '비', '씨', '씨', '디', '디', '이', '이', '에프', '에프', '쥐', '쥐', '에이치', '에이치', '아이', '아이', '제이',
'제이',
'케이', '케이', '엘', '엘', '엠', '엠', '엔', '엔', '오', '오', '피', '피', '큐', '큐', '알', '알', '에스', '에스', '티', '티', '유',
'유', '브이', '브이',
'더블유', '더블유', '에스', '에스', '와이', '와이', '지', '지']
trans = dict(zip(ENGS, KORS)) # 영어와 한글을 대칭하여 딕셔너리화
is_english = re.compile('[-a-zA-Z]') # 영어 정규화
temp = is_english.findall(input_text) # 함수에 들어오는 인자가 영어가 있는경우 temp에 삽입
result_trans = []
if len(temp) > 0: # 영어가 temp에 존재하는 경우
result_trans = ''.join([trans[i] for i in temp]) # 영어를 한글자씩 한글로 매칭
return result_trans # 매칭된값 리턴
else:
return None발음 그대로 표기하여 매칭해주는 부분이다.
a = simple_filter("SKT")
a
확장
파파고 API를 사용하는데 고유명사 등 처리가 안될경우 그 부분만 번역을 해주어 리턴해주는 방법을 고안
파파고 API는 무료버전을 사용
import requests
def get_translate(text):
client_id = "" # <-- client_id 기입
client_secret = "" # <-- client_secret 기입
data = {'text' : text,
'source' : 'en',
'target': 'ko'}
url = "https://openapi.naver.com/v1/papago/n2mt"
header = {"X-Naver-Client-Id":client_id,
"X-Naver-Client-Secret":client_secret}
response = requests.post(url, headers=header, data=data)
rescode = response.status_code
if(rescode==200):
send_data = response.json()
trans_data = (send_data['message']['result']['translatedText'])
return trans_data
else:
print("Error Code:" , rescode)def start_trans(input_text):
ENGS = ['a', 'A', 'b', 'B', 'c', 'C', 'd', 'D', 'e', 'E', 'f', 'F', 'g', 'G', 'h', 'H', 'i', 'I', 'j', 'J', 'k',
'K', 'l', 'L',
'm', 'M', 'n', 'N', 'o', 'O', 'p', 'P', 'q', 'Q', 'r', 'R', 's', 'S', 't', 'T', 'u', 'U', 'v', 'V', 'w',
'W', 's', 'S', 'y', 'Y', 'z', 'Z']
KORS = ['에이', '에이', '비', '비', '씨', '씨', '디', '디', '이', '이', '에프', '에프', '쥐', '쥐', '에이치', '에이치', '아이', '아이', '제이',
'제이',
'케이', '케이', '엘', '엘', '엠', '엠', '엔', '엔', '오', '오', '피', '피', '큐', '큐', '알', '알', '에스', '에스', '티', '티', '유',
'유', '브이', '브이',
'더블유', '더블유', '에스', '에스', '와이', '와이', '지', '지']
trans = dict(zip(ENGS, KORS))
papago_trans = get_translate(input_text) # 파파고로 번역 데이터 보내기
is_english = re.compile('[-a-zA-Z]')
temp = is_english.findall(papago_trans) # 파파고에서 번역이 안된 영어 문장이 있다면 temp값 존재
result_trans = []
if len(temp) > 0: # 영어 데이터 존재 유무
result_trans = ''.join([trans[i] for i in temp])
return result_trans # 한글로 번역이 안된 데이터 존재
else:
return papago_trans # 한글로 번역이 잘된 데이터일 경우 그대로 리턴
a = start_trans("SKT")
a
기존에 영어 데이터가 없다면 파파고에서 출력된 값이 출력될 것이고 번역이 안됬다면 매칭된 결과값이 출력될 것이다.
a = start_trans("naver")
a
a = start_trans("SKT T1")
a
숫자 데이터 같은 경우에는 필터링되므로 필터 부분에 적당한 조율을 하면 될것 같다.
다음 편에선 파파고 API의 비동기화를 다뤄보겠다.
반응형