
AI를 이용한 정적 분석만으로 악성코드의 특징들을 찾아내어 동적 분석 없이 높은 탐지율로 악성코드를 추출해냈다.
학습에 사용한 데이터는 peframe으로 파일들의 특성을 추출하였으며, 데이터 전처리와 분석은 word2vec 모델을 사용하였다.
학습 모델은 LGBM 을 사용하였으며, 입력 벡터는 word2vec 모델을 사용하여 학습을 진행했다.
악성코드 탐지 및 특성 추출 방법
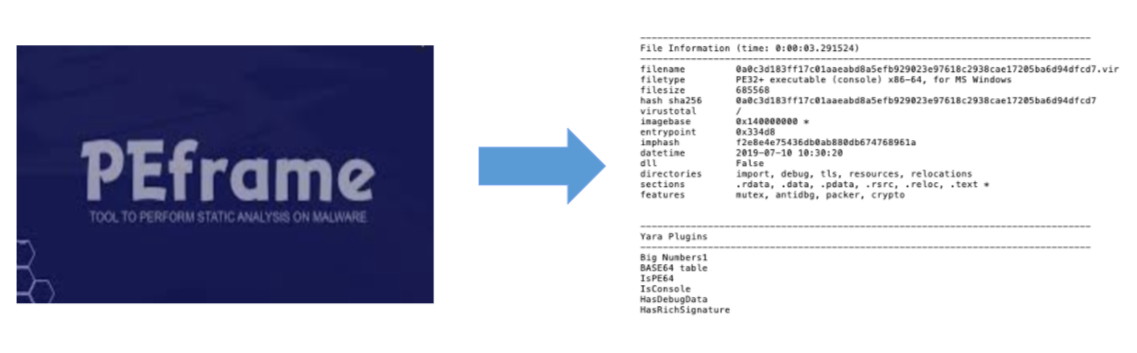
PEFrame을 통해 파일에 대한 데이터를 정적 분석하여 해당 파일의 특성들을 전부 추출하여 사용하였다
파일 하나당 한 개의 텍스트 파일에 정적 분석 데이터를 담았으며, 총 1만개의 텍스트 파일이 존재한다.

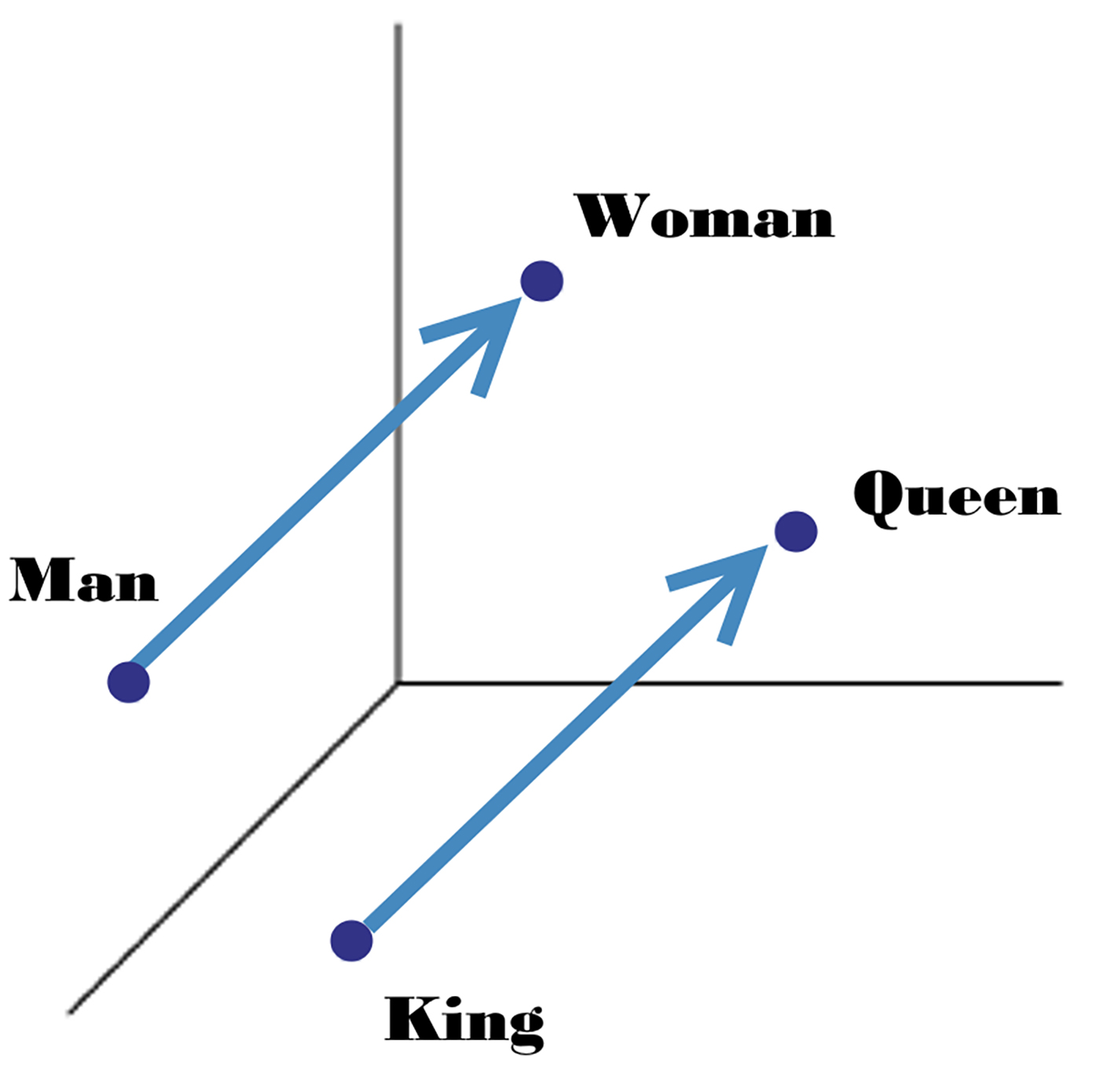
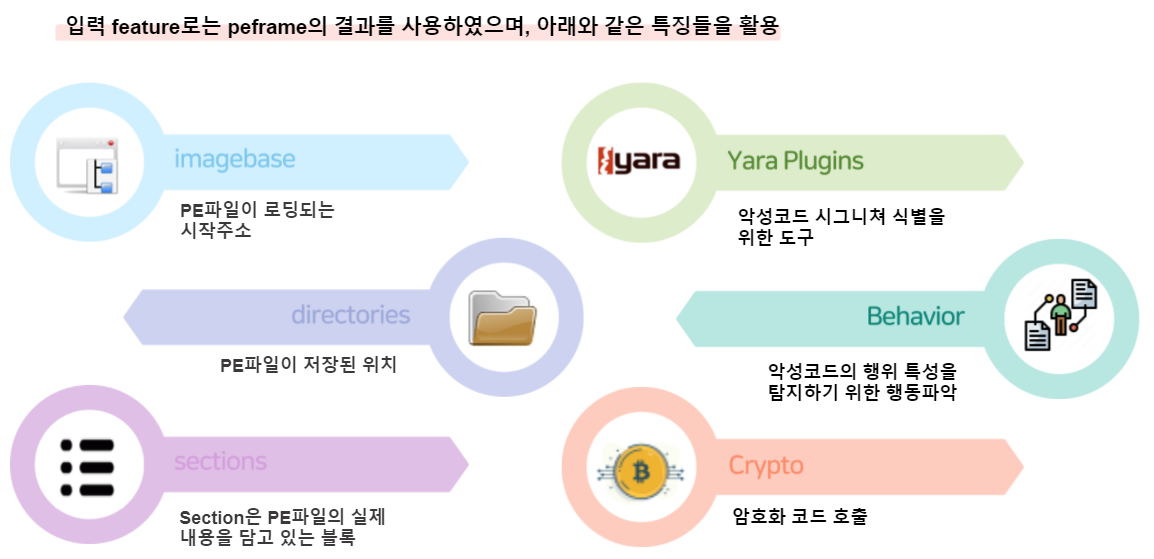
PeFrame 분석 결과를 모델에 돌리기 위해서
단어 임베딩 방법론 중 하나인 Word2Vec을 활용하였다.
사용목적
1. 추출된 단어를 벡터화 하기 위해서
2. PE 파일 헤더에서 추출한 api 함수 및 각종 정보에서 나온 유사한 단어들을 묶기 위해
3. 악성 코드에서 호출한 함수등은 비슷한 방향으로 묶일 것으로 예측
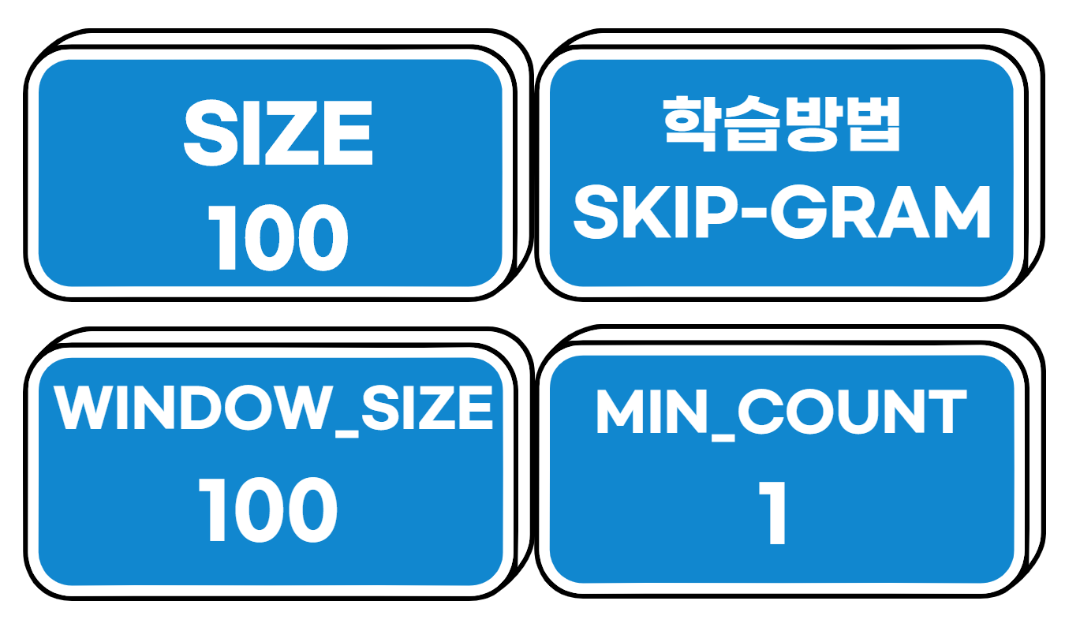
학습 방법은 skip-gram
문장 단위는 100으로 설정
등장한 모든 단어를 사전으로 만들기 위해 min_count 옵션을 1로 설정
모든 단어는 100차원으로 학습

word2vec을 사용해 입력 데이터 벡터화
- 사용한 머신러닝 알고리즘 RandomForest, Xgboost, LGBM 등 모두 2D 입력을 가짐
- word2vec으로 학습된 단어는 각 100차원을 가진다.
- 2D 입력 값을 만들기 위해 100차원 벡터의 평균값으로 변환해서 사용하였다.
- 입력 feature는 모든 단어장, 즉 283,105개의 단어를 활용하였다.
- 결국 입력 데이터의 shape은 (입력 데이터 수(10000개), vocab_size(283105개))
탐지 알고리즘 – word2vec 변환 예시

탐지 알고리즘 – word2vec

탐지 알고리즘 – word2vec visualize



실험

Data split
Dataset size : 10,000
Train data size : 8,000
Test data size : 2,000
Word2Vec + lightgbm알고리즘 평가

결론 (탐지 흐름도)
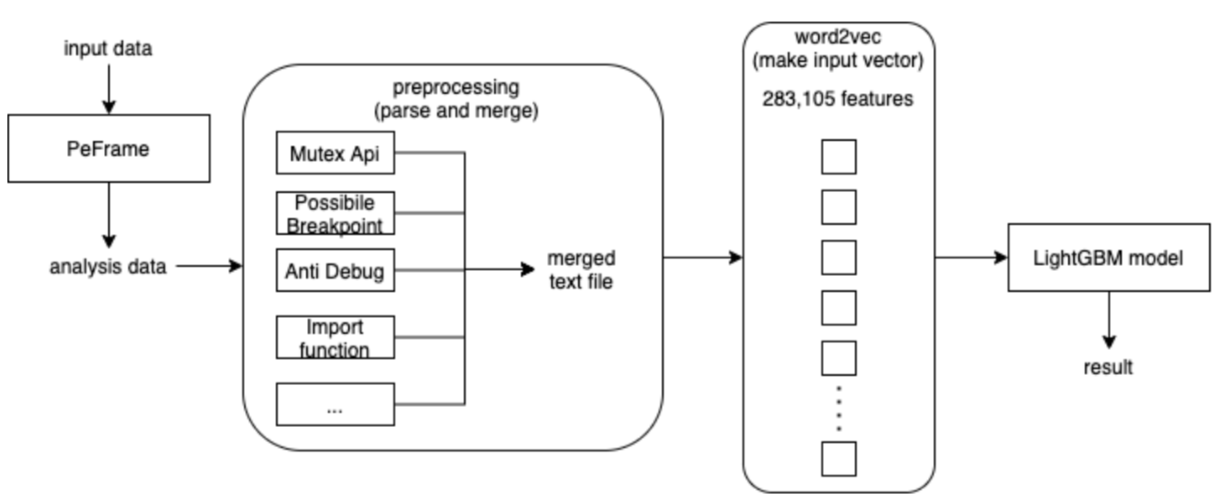
결론

AI를 이용한 정적 분석만으로 악성코드의 특징들을 찾아내어 동적 분석 없이 높은 탐지율로 악성코드를 추출해냈다.
학습에 사용한 데이터는 peframe으로 파일들의 특성을 추출하였으며, 데이터 전처리와 분석은 word2vec 모델을 사용하였다.
학습 모델은 LGBM 을 사용하였으며, 입력 벡터는 word2vec 모델을 사용하여 학습을 진행했다.
악성코드 탐지 및 특성 추출 방법
PEFrame을 통해 파일에 대한 데이터를 정적 분석하여 해당 파일의 특성들을 전부 추출하여 사용하였다
파일 하나당 한 개의 텍스트 파일에 정적 분석 데이터를 담았으며, 총 1만개의 텍스트 파일이 존재한다.
PeFrame 분석 결과를 모델에 돌리기 위해서
단어 임베딩 방법론 중 하나인 Word2Vec을 활용하였다.
사용목적
1. 추출된 단어를 벡터화 하기 위해서
2. PE 파일 헤더에서 추출한 api 함수 및 각종 정보에서 나온 유사한 단어들을 묶기 위해
3. 악성 코드에서 호출한 함수등은 비슷한 방향으로 묶일 것으로 예측
학습 방법은 skip-gram
문장 단위는 100으로 설정
등장한 모든 단어를 사전으로 만들기 위해 min_count 옵션을 1로 설정
모든 단어는 100차원으로 학습
word2vec을 사용해 입력 데이터 벡터화
- 사용한 머신러닝 알고리즘 RandomForest, Xgboost, LGBM 등 모두 2D 입력을 가짐
- word2vec으로 학습된 단어는 각 100차원을 가진다.
- 2D 입력 값을 만들기 위해 100차원 벡터의 평균값으로 변환해서 사용하였다.
- 입력 feature는 모든 단어장, 즉 283,105개의 단어를 활용하였다.
- 결국 입력 데이터의 shape은 (입력 데이터 수(10000개), vocab_size(283105개))
탐지 알고리즘 – word2vec 변환 예시
탐지 알고리즘 – word2vec
탐지 알고리즘 – word2vec visualize
실험
Data split
Dataset size : 10,000
Train data size : 8,000
Test data size : 2,000
Word2Vec + lightgbm알고리즘 평가
결론 (탐지 흐름도)
결론