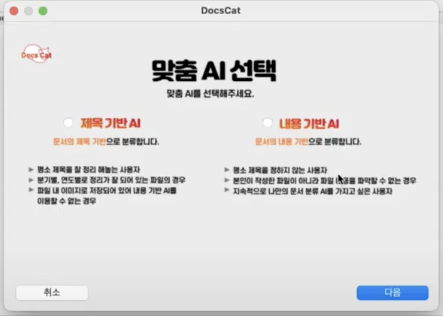
최종적인 문서 및 파일 자동 분류 프로그램이 완성되었습니다.
AI를 이용했다기 보단 필터링에 더 집중이 많이되었습니다
한국에서는 위와 같은 자동 분류 프로그램이 많이 없는걸로 알고 있는데
의미있게 코드들을 수정해주시면 감사하겠습니다.
# 제목 기반 자동 분류
def title_classification(directory_list, file_list):
result_dict = {}
index_dict = {}
origin_directory_list = directory_list.copy()
origin_file_list = file_list.copy()
# 첫번째 단계 : 데이터 전처리 (data preprocess)
tmp_dir_list = data_preprocess(directory_list)
tmp_file_list = data_preprocess(file_list)
# 두번째 단계 : 단순 유사도 검사 (simplest_classification)
index_dict = simplest_classification(tmp_dir_list, tmp_file_list)
## Save classificated file
result_dict.update(save_classificated_file(index_dict, origin_file_list, origin_directory_list))
### Remove classificated file
tmp_file_list = rm_classificated_file(index_dict, tmp_file_list)
origin_file_list = rm_classificated_file(index_dict, origin_file_list)
# 세번째 단계 : Word2Vec를 이용한 유사도 검사 (word2vec_similarity)
index_dict = word2vec_similarity(tmp_dir_list, tmp_file_list)
## Save classificated file
result_dict.update(save_classificated_file(index_dict, origin_file_list, origin_directory_list))
### Remove classificated file
tmp_file_list = rm_classificated_file(index_dict, tmp_file_list)
origin_file_list = rm_classificated_file(index_dict, origin_file_list)
# 네번째 단계 : 자모단위 유사도 검사 (Phonology classification)
index_dict = Phonology_classification(tmp_dir_list, tmp_file_list)
## Save classificated file
result_dict.update(save_classificated_file(index_dict, origin_file_list, origin_directory_list))
### Remove classificated file
tmp_file_list = rm_classificated_file(index_dict, tmp_file_list)
origin_file_list = rm_classificated_file(index_dict, origin_file_list)
# 다섯번째 단계 : 예외 처리 (except_directory)
result_dict.update(except_directory(origin_file_list))
# Change dictionary to result
result_list = dict_to_list(result_dict)
return result_list
사전에 설치
!pip3 install konlpy
!pip3 install jamoimport re
import jpype
import requests
from gensim.models import Word2Vec
from jamo import h2j, j2hcj
from konlpy.tag import Okt1. 데이터 전처리
우선 첫번째 단계인 데이터 전처리 단계이다.
tmp_dir_list = data_preprocess(directory_list)
tmp_file_list = data_preprocess(file_list)
입력할 폴더명과 파일명의 데이터를 전처리해준다.
전처리 과정은 파일리스트들과 디렉토리 리스트 내의 각 명칭에 대한 확장자 제거해주고 그다음 번역을 해준다.
기존 파일명들의 이름이 바뀌지 않게 temp 를 설정하여 폴더명과 파일명들을 유지시키게 하였다.
def data_preprocess(data_list): # 파일 리스트 / 디렉토리 리스트 내의 각 명칭에 대한 확장자 제거 및 영어 번역
preprocessed_list = data_list
tmp_data=""
result = []
for data_index in range(len(preprocessed_list)):
split_data = morpheme(preprocessed_list[data_index])
preprocessed_list[data_index] = split_data
for index in range(len(preprocessed_list)):
eng_list = get_translate_eng(preprocessed_list[index])
ko_list = get_translate_ko(eng_list)
result.append(ko_list)
return result전번적인 데이터 전처리 (메인)
1. morpheme 함수 : 확장자 및 특수문자 제거
2. get_translate_eng , get_translate_ko : 영어일 경우 한글로 변환
여기서 왜 번역을 두번 사용 하는가?
예를들어 파일명이나 폴더명이 '민주당미래법제상임위원회회의.txt'
라는 파일명이 있다고 가정하면
Word2Vec에선 해당 단어를 처리할 수가 없다.
고유명사에 대한 띄어쓰기 모델도 적당한게 없어서 AI 번역기인 파파고를 이용하여 자동으로 띄어쓰기 하기 위해 번역을 두번 하였다
(두번의 번역을 돌렸을때 생기는 오역들의 경우 한글 모델이 아닌 영어 모델을 사용하면 오역의 횟수가 줄어든다.)
결과 : 민주당 미래 법제상임위원회 회의
(고유명사 처리)
def morpheme(file_name): # 파일 확장자 및 특수문자 제거 후 형태소 명사 단위로 분석
okt = Okt()
no_extension_file_name = file_name.rsplit('.', 1)[0]
cleaned_file_name = re.sub('[-=+,_#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`\'…》]', '', no_extension_file_name)
return cleaned_file_name
파일의 확장자와 특수문자를 제거 해주고 형태소 명사 단위로 분석 (서브)
def get_translate_eng(text):
client_id = "클라이언트 아이디"
client_secret = "클라이언트 시크릿키"
data = {'text': text,
'source': 'ko',
'target': 'en'}
#url = "https://openapi.naver.com/v1/papago/n2mt"
url = "https://naveropenapi.apigw.ntruss.com/nmt/v1/translation"
header = {"X-NCP-APIGW-API-KEY-ID": client_id,
"X-NCP-APIGW-API-KEY": client_secret}
response = requests.post(url, headers=header, data=data)
rescode = response.status_code
if (rescode == 200):
t_data = response.json()
to_trans = (t_data['message']['result']['translatedText'])
return to_trans
else:
print("Error Code:", rescode)
def get_translate_ko(text):
client_id = "클라이언트 아이디"
client_secret = "클라이언트 시크릿키"
data = {'text': text,
'source': 'en',
'target': 'ko'}
url = "https://naveropenapi.apigw.ntruss.com/nmt/v1/translation"
header = {"X-NCP-APIGW-API-KEY-ID": client_id,
"X-NCP-APIGW-API-KEY": client_secret}
response = requests.post(url, headers=header, data=data)
rescode = response.status_code
if (rescode == 200):
t_data = response.json()
to_trans = (t_data['message']['result']['translatedText'])
return to_trans
else:
print("Error Code:", rescode)번역 부분은 이전에 올렸던 파파고 API를 이용한 비동기화를 적용하면 번역 시간을 대폭 단축해준다.
[AI 문서 분류] 파이썬을 이용한 파파고API 비동기화
!pip install aiohttp 비동기화를 설명하기 이전에 지난번 작성했던 번역 부분을 보겠다. a = start_trans("naver") a 번역해서 돌아오는 시간을 계산해본 결과 1~2초 정도 걸렸다 하지만 10개의 데이터를 보내
bziwnsizd.tistory.com
파일명이나 폴더명이 영어일 경우 한글로 변환 (서브)


전처리 단게에서는 위와 같은 결과가 나온다
파일명 같이 파일명이 긴 경우에 두번을 번역하기 때문에 오역이나 번역이 안될 수도 있음에 주의
2. 단순 유사도 검사
말그대로 파일명과 폴더명이 완전히 같을 경우 그 폴더안에 파일을 넣어주는 방식
def simplest_classification(directory_list, file_list): # 단어 유사도 검사 => index return해서 제거하는 방법을 쓴다.
tmp_dict = {}
if jpype.isJVMStarted():
jpype.attachThreadToJVM()
okt = Okt()
classificated_dir_index = 0
for file_index in range(len(file_list)):
file_morphs = okt.morphs(file_list[file_index])
max_weight = 0
for dir_index in range(len(directory_list)): # 디렉토리 갯수 : 3
dir_morphs = okt.morphs(directory_list[dir_index])
tmp_weight = 0
for file_element in file_morphs: # 형태분석한 파일 갯수
for dir_element in dir_morphs:
if (dir_element == file_element) and (check_format(dir_element) == ('kor')):
tmp_weight += 2
#한글로 되있을 경우 가중치 2
elif ((file_element in dir_element) and (check_format(dir_element) == ('num'))):
tmp_weight += 1
#영어로 되있을 경우 가중치 1
if (tmp_weight > max_weight):
max_weight = tmp_weight
classificated_dir_index = dir_index
if max_weight > 0:
tmp_dict[file_index] = classificated_dir_index
return tmp_dict
check_format 함수를 통해 해당 한글과 숫자를 판단하고 가중치를 주어 넣어주는 부분이다
예를들면 '2021 제무제표' 라는 파일이있을경우
내가 '2021' 폴더와 '제무제표' 폴더를 설정했다면 한글의 가중치가 더 높은 '제무제표'에 들어가게끔 만들었다.
save_classificaticated_file 함수를 통해 폴더 안에 들어간 파일의 내용들을 저장 시킨다.
def save_classificated_file(index_dict, file_list, directory_list):
result_dict = {}
for key, value in index_dict.items():
result_dict[file_list[key]] = directory_list[value]
return result_dict
rm_classificaticated_file 함수를 통해 매칭된 파일들을 제거한다.
분류가 안된 파일들이 있다면 다음 단계로 넘어간다.
def rm_classificated_file(index_dict,file_list): # 매칭된 파일 제거
data_name = []
for index in list(index_dict.keys()):
data_name.append(file_list[index])
file_list = [x for x in file_list if x not in (data_name)]
return file_list
3. Word2Vec를 이용한 유사도 검사
word2vec 모델을 이용하여 폴더명과 파일명의 유사도를 비교한다.
모델은 위키백과 한글 모델을 사용하였고 해당 모델은 아래 링크를 참고하였다.
한국어 임베딩
한국어 임베딩 관련 튜토리얼 페이지입니다.
ratsgo.github.io
def word2vec_similarity(directory_list, file_list):
model = Word2Vec.load('모델 경로')
tmp_dict = {}
classificated_dir_index = 0
if jpype.isJVMStarted():
jpype.attachThreadToJVM()
okt = Okt() # 형태소 분석
for file_index in range(len(file_list)):
max_similarity = 0
file_morphs = okt.morphs(file_list[file_index])
for dir_index in range(len(directory_list)):
dir_morphs = okt.morphs(directory_list[dir_index])
tmp_similarity = 0
for file_element in file_morphs:
for dir_element in dir_morphs:
if check_format(file_element) == 'kor' and check_format(dir_element) == 'kor':
try:
tmp_similarity = model.similarity(file_element, dir_element)
except KeyError:
pass
if tmp_similarity > max_similarity: # 유사도 수치는 사용자가 설정
max_similarity = tmp_similarity
classificated_dir_index = dir_index
tmp_dict[file_index] = classificated_dir_index
return tmp_dictWord2Vec 특성을 활용하여 단어와 단어 사이의 유사를 측정하고 측정 퍼센테이지를 출력해준다
우리의 경우에는 폴더명과 파일명의 유사도를 측정하는데 사용한다.
위와 같이
save_classificaticated_file 함수를 통해 폴더 안에 들어간 파일의 내용들을 저장 시킨다.
rm_classificaticated_file 함수를 통해 매칭된 파일들을 제거한다.
분류가 안된 파일들이 있다면 다음 단계로 넘어간다.
4. 자모 단위를 이용한 유사도 검사
이전에 작성하였던 자모 단위 필터링을 활용하였다.
필터링의 강도에 따라 예외처리가 얼마나 발생하느냐는 사용자의 설정에 조절할 수 있다.
[AI 문서 분류] 파이썬을 이용한 자모 단위 필터링
자모단위로 분류하는 알고리즘 구현 -정확도 낮음 jamo 모듈은 글자를 자모단위로 쪼개주는 역할을 한다 아 -> ㅇ + ㅏ 자소서 -> ㅈ + ㅏ + ㅅ + ㅗ + ㅅ + ㅓ 예를 들어 폴더명을 자소서라고 짓는다
bziwnsizd.tistory.com
def Phonology_classification(directory_list, file_list):
trans_file_jumo = []
trans_folder_jumo = []
equl_count = [[0 for i in range(len(file_list))] for i in range(len(directory_list))]
result_dict = {}
for i in file_list:
a = j2hcj(h2j(i))
line = []
for j in a:
line.append(j2hcj(h2j(j)))
trans_file_jumo.append(line)
for i in directory_list:
a = j2hcj(h2j(i))
line = []
for j in a:
line.append(j2hcj(h2j(j)))
trans_folder_jumo.append(line)
for i in range(len(directory_list)):
for j in range(len(file_list)):
for k in trans_file_jumo[j]:
if k in trans_folder_jumo[i]:
equl_count[i][j] += 1
for i in range(len(directory_list)):
for j in range(len(file_list)):
if len(trans_folder_jumo[i]) <= equl_count[i][j]:
result_dict[j] = i
return result_dict
위와 같이
save_classificaticated_file 함수를 통해 폴더 안에 들어간 파일의 내용들을 저장 시킨다.
rm_classificaticated_file 함수를 통해 매칭된 파일들을 제거한다.
분류가 안된 파일들이 있다면 다음 단계로 넘어간다.
5. 기타 폴더
모든 단계에서 분류가 안되어 남은 파일들은 기타 폴더로 넣어주는 작업이다.
해당 작업은 위의 유사도 측정에 따라 많이 들어갈수도 적게 들어갈수도 있는 부분이다.
필터링의 부분을 강하게 주었다면 기타폴더에 거의 들어가지 않을것이고, 약하게 주었다면 기타 폴더에 많이 들어갈 것이다.
def except_directory(file_list):
out_of_classification = "except_directory"
result_dict = {}
for file in file_list:
result_dict[file] = out_of_classification
return result_dictdef dict_to_list(dict):
result = []
for key, value in dict.items():
tmp = str(value) + "/"+ str(key)
result.append(tmp)
return result
6. 결과
입력한 값
directory_list = ['넷마블', '대통령', '민주당', '모모랜드', '레드벨벳', '빅히트', '소프트', '코스피', '텔레콤', '트롯', '포토']
file_list = ['코스피외국인개인매수에코앞까지코스닥돌파.txt', '더불어민주당미래입법과제상임위간사단연석회의.txt', '자급제아이폰분실보험가입일부터가능.txt', '모모랜드주이자가격리붐대신스페셜등장어마어마하게떨려붐붐파워.txt', '넷마블월드시즌챕터업데이트.txt', '코스피사흘연속사상최고치경신.txt', '민주당미래입법과제상임위간사단연석회의.txt', '텔레콤맵안드로이드오토베타테스트론칭.txt', '놀면뭐하니톱귀유재석추억의주크박스오픈만여명과깜짝라이브.txt', '발라드그룹순순희신곡전부다주지말걸발표.txt', '트롯신홍원빈테스형으로열정무대패자부활전탈락에도극찬.txt', '넷마블월드새로운챕터성카드추가.txt', '코스피는오르고환율은내리고.txt', '자급제아이폰써도분실보험가입가능해진다.txt', '장동민배다해선넘는사생활피해에곤혹이슈톡.txt', '코스피사상최고치경신.txt', '다시뒤집힌전동킥보드법무면허규제법행안위통과.txt', '빅히트레이블즈가지테마로펼쳐진다.txt', '자급제아이폰일부터분실보험가입가능.txt', '코스피사상최고치.txt', '텔레콤자급제아이폰도분실보험가입된다.txt', '소프트웨이브디지털전환사이버보안이핵심.txt', '이낙연공수처법반드시완수많이인내했고결단임박.txt', '세일즈포스고급차브랜드벤틀리에솔루션공급.txt', '코스피다시역대최고가마감.txt', '모모랜드주이붐붐파워대타상큼미모.txt', '코스피종가기준최고치경신.txt', '미래입법과제상임위간사단연석회의참석하는이낙연김태년.txt', '대통령절차적정당성공정성당부추미애징계위연기.txt', '레드벨벳아이린오랜만에근황화보촬영스타.txt', '코스피마감사흘연속사상최고치경신.txt', '코스피일째사상최고원달러환율원대.txt', '소프트웨이브플렌옵틱콘텐츠저작기술.txt', '트롯신이떴다홍원빈테스형으로레전드무대선사.txt', '미래입법과제발언하는이낙연대표.txt', '코스피일연속최고치경신선목전서마감종합.txt', '코스피마감또최고치경신선눈앞.txt', '코스피거침없는질주오르며사흘째최고치경신.txt', '민주당국회자리에아파트짓자는건토건포퓰리즘.txt', '포토하하별후딱끝내고갈게.txt', '표시장거래현황.txt', '크루미디어지콤위시트레이닝센터업무제휴계약체결.txt', '민주당미래입법과제연석회의.txt', '대통령절차적정당공정성강조에징계위일로연기.txt', '코스피하루만에최고치경신.txt', '윤보미김민경비장함감도는마녀들포스터운동신들케미에기대.txt', '발언하는이낙연대표.txt', '대통령이용구징계위원장배제지시했지만공정성논쟁은여전.txt', '미래입법과제상임위간사단연석회의.txt', '자급제아이폰고객도분실보험가입된다.txt', '모모랜드낸시나윤한복전도사뿜뿜.txt', '대화하는이낙연한정애.txt', '텔레콤빅테크마케팅컴퍼니로조직개편.txt', '레드벨벳아이린갑질논란후첫근황미모에물올랐네스타.txt', '코스피최고치경신눈앞삼성전자장중만원첫돌파.txt', '소프트웨이브모아소프트등분석시험도구공개.txt', '빅히트뉴이어스이브라이브.txt', '목요대화참석자와인사하는정세균총리.txt', '코스피사상최고치원달러환율원붕괴.txt', '소프트웨이브혁신기술선보인다스타트업총출동.txt', '소프트웨이브플랫폼부터의료진단시스템까지신기술총출동.txt', '자급제아이폰도일부터분실보험가입가능.txt', '김태희싸이다이아몬드수저스타상위집안연중라이브.txt', '목소리내는여당전의원들추미애가검찰개혁어렵게해.txt', '자급제아이폰분실보험가입월일부터가능.txt', '발언하는김태년원내대표.txt', '코스피일째사상최고치.txt', '코스피사흘연속사상최고치경신선눈앞.txt', '트롯전국체전트로트전쟁서막알리는예고편공개.txt', '코스피역대최고가로마감.txt', '트롯전국체전레전드라인업과함께트로트시대연다.txt', '빅히트패밀리콘서트에서도본다새해카운트다운무대공개.txt', '자급제아이폰도분실보험가능.txt', '민주당권력기관개혁마무리수순야당공수처결사반대.txt', '소프트웨이브국내대표솔루션업계차세대먹거리로미래준비한다.txt', '코스피일째사상최고선코앞.txt', '스브스타남자로살겠다선언한엘리엇페이지에배우자도지지자랑스러워.txt', '단독박명수이찬원밀접접촉자개뼈다귀녹화연기.txt', 'untitled.ui', '민주국민의힘김은혜대변인즉각적인사과촉구.txt', '미래입법과제연석회의참석하는이낙연김태년.txt']
초반에 작성하였던 임의의 폴더명과 파일명들을 통해 위의 모든 단계를 거쳐 나온 결과물

7. 마무리
위의 내용은 팀 프로젝트에서 작업했던 초기버전 즉, 첫번째 버전이다.
최종적으로 만들었던 코드보다 덜 정교하지만 위의 내용또한 의미있는 코드라 생각하여 작성해보았다.
우리는 윈도우 및 Mac용 어플리케이션을 제작하여 사용자가 직접 사용할 수 있게 해보았고, 성능 또한 괜찮다는 평을 받았었다.

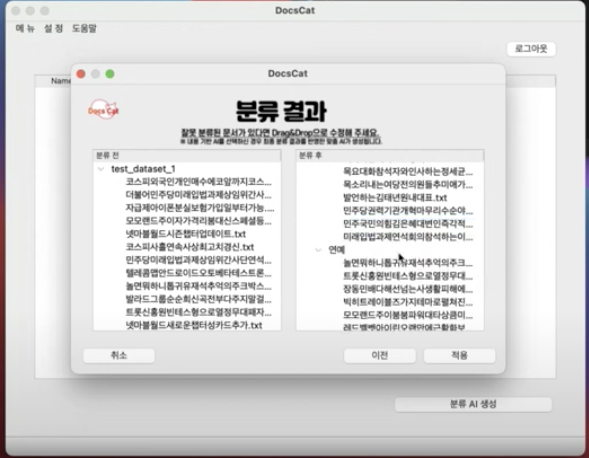
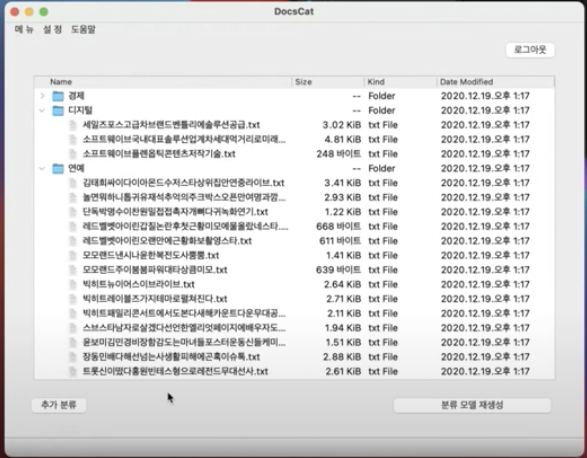

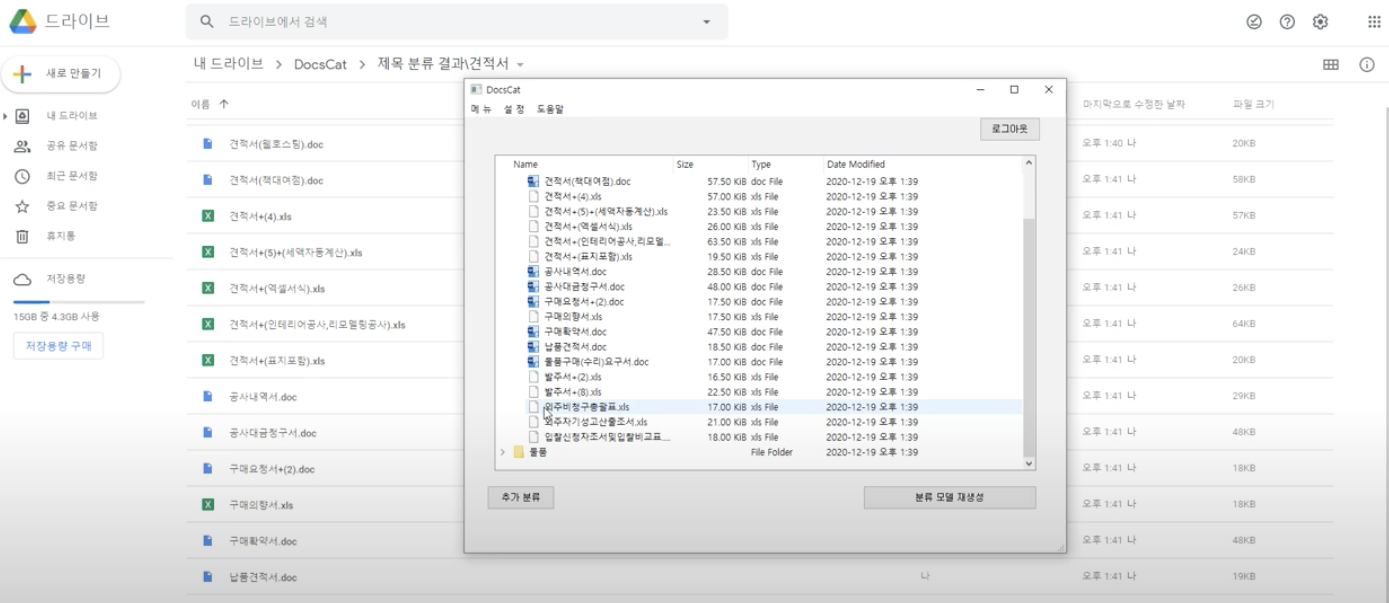
또한 구글 드라이브에 있는 파일이나 폴더를 다운받아 분류해주며,
최종적으로 분류된 내용을 구글로 다시 업로드 시킬 수 있는 기능을 추가하였다.
해당 글은 제목 기반의 분류만 작성하였고, 내용 기반 분류는 시간이 된다면 추후에 작성 할 예정이다.